팀에서 관리중인 여러 프로젝트의 모니터링을 위해 도입한 Prometheus 에 대해 정리해보도록 하겠습니다.
- Prometheus
Prometheus 는 메트릭 기반의 오픈소스 모니터링 시스템입니다. (공식 페이지)
제가 다른 모니터링 시스템을 사용해보진 않아 직접적인 비교는 어렵지만, 사용이 어렵지 않습니다.
또한 많은 관심을 받고 있는 Kubernetes 의 서비스 모니터링에도 사용되고 있습니다.

공식 페이지에서 소개하고 있는 Prometheus 의 특징들 입니다. 간략하게 정리해보겠습니다.
- 고차원 데이터 모델을 구현, 시계열은 메트릭 이름과 key-value 쌍으로 식별됨
- PromQL 을 통한 강력한 쿼리들
- 뛰어난 데이터 시각화 (with Grafana)
- custom format 을 통해 효율적인 데이터 저장
- 각 서버는 안정성을 위해 독립적이며 로컬 저장소에만 의존
- 정확한 alert
- 많은 클라이언트 라이브러리들
- pull 방식의 데이터 수집 (push 방식도 가능)
- Prometheus 구조

검색을 하면 주로 나오는 Prometheus 구조도에서 Service discovery 만 제외한 구조도입니다.
한 파트씩 정리해보겠습니다.
• Jobs/exporters
exporter 는 Prometheus 가 pull 방식으로 데이터를 수집할 수 있도록 메트릭을 노출하는 agent 입니다.
이 exporter 가 서버들로부터 메트릭을 수집해 /metrics HTTP endpoint 를 제공합니다. 그러면 Prometheus 는 exporter 가 열어놓은 HTTP endpoint 로 GET 요청을 날려 메트릭을 수집하는 것입니다. (Pull 방식)
고로 이 방식이 가능하게 하기 위해선 우리가 모니터링을 할 서버에 exporter 가 설치되어 있어야 합니다.

위 사진은 exporter 중 하나인 Node exporter 입니다.
Node exporter 는 Cpu, Memory, Disk 등과 같은 다양한 하드웨어 상태와 커널 관련 정보들을 메트릭으로 수집하고 api 로 제공합니다.
예를 들어 AWS ec2 instance 에 Node exporter 가 설치되어있다면 Prometheus 는 해당 ec2 에 접근해 위와 같은 정보들을 수집할 수 있게 됩니다.
• PromQL & Visualization
Prometheus 가 수집해서 TSDB 에 저장되어 있는 데이터는 PromQL 을 통한 쿼리를 통해 조회가 가능하고, Prometheus 가 자체적으로 제공하는 web UI 에서 테이블 및 그래프 형태로 볼 수 있습니다.
하지만 이 UI 는 시각화에 부족함이 있어 Grafana 라는 tool 을 많이 사용합니다. (Prometheus 도 자체 UI 를 추천하지 않는다고 합니다..)


간단한 그래프 하나를 예시로 가져왔습니다. 시각화에 대한 차이는 단순히 이렇게 보기에도 커 보입니다.
또한 Grafana 에선 아래에서 설명할 Prometheus Alertmanager 와 별도로 Alert 를 생성할 수 있습니다.
• Alertmanager
Prometheus 가 제공하는 Alertmanager 를 통해 각 모든 지표마다 조건을 걸고 다양한 채널로 Alert 를 보낼 수 있습니다.
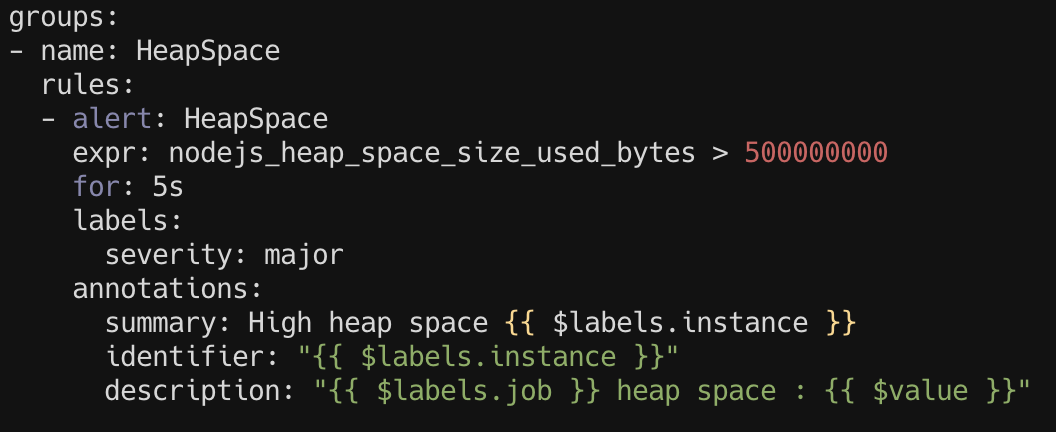
자세하게 다루진 않겠지만 대략 위처럼 alert rule file 을 작성해 expr 에 명시한 조건이 for 에 명시한 기간 이상 발생한 경우 알람을 발생시키고 이메일, 슬랙등의 채널로 받을 수 있습니다.
• Pushgateway
기본적으로 Prometheus 는 Pull 방식을 통해 메트릭을 수집합니다만, 위에서 설명한 것처럼 Prometheus 가 exporter 를 통한 HTTP endpoint 에 접근이 안되는 곳에는 Pull 방식의 수집이 불가합니다 (ex. batch-job).
이럴 경우 대안으로 Pushgateway 를 사용할 수 있습니다. 나중에 자세히 보겠지만 간단히 설명하자면,
app 은 Pushgateway 로 메트릭을 Push 하고, Prometheus 는 Pushgateway 에 접근해 쌓인 메트릭을 Pull 하는 방식입니다.
• Service discovery
Service discovery 는 Prometheus 가 메트릭을 수집할 대상을 동적으로 설정하는 것을 가능하게 해줍니다.
이를 통해 오토 스케일링되는 ec2 instances 나 kubernetes pods 으로부터 메트릭 수집이 가능합니다만,
(만약 정적 설정만 가능했다면 추가된 서버, 혹은 서버가 내려갔을 시 수집이 불가능했을 것입니다)
차후에 따로 다루기 위해 제가 그린 구조도에서는 제외했습니다.
- Metric
위의 설명에서 계속 나오는 메트릭이 무엇인지 간단하게 정리해 보겠습니다.
메트릭은 일반적으로 타임스탬프와 한두가지 숫자값 을 포함하는 이벤트입니다.
Prometheus 는 근본적으로 모든 데이터를 시계열로 저장하고, 모든 시계열 데이터는 고유한 메트릭명 과 옵셔널하게 들어갈 수 있는 key-value 쌍의 라벨로 구분됩니다.
메트릭명{라벨명=값, 라벨명=값} 샘플링 데이터
간단히 나타내면 Prometheus 의 메트릭은 위처럼 구성되어 있습니다. 예시를 보자면 아래와 같습니다.

node_cpu_seconds_total 이라는 메트릭명에, cpu 와 mode 라는 라벨이 붙어있습니다.
cpu 와 mode 라벨에 각각 0, idle 라는 값을 가진 메트릭 값은 48649.88 입니다.
이 데이터가 Prometheus 에 수집되어 저장될 때 timestamp 값이 같이 들어가게 되고,
이렇게 쌓인 메트릭 데이터들을 시계열 데이터 라고 합니다.
라벨은 옵션이라서, 아래와 같이 메트릭명 과 값으로만 구성된 형태도 가능합니다.

- Metric type
Prometheus 에는 크게 4가지의 메트릭 타입이 존재합니다. 간략하게만 보고 가겠습니다.
• counter : 증가하거나 0 으로만 리셋 가능 (ex. total request count)
• gauge : 증감 혹은 특정 값으로 설정 가능 (ex. number of running processes)
• histogram : 특정 범위 (bucket) 내에서 값의 빈도수를 표현 (ex. request duration)
• summary : histogram 과 유사, 사분위수를 나타냄 (ex. request duration)
이렇게 4가지 타입이 있으며, 보다 자세한 설명은 차후 예시를 통해 하도록 하겠습니다.
여기까지 Prometheus 가 무엇이고, 어떻게 구성되어있는지, 메트릭은 무엇인지에 대해 정리해봤습니다.
다음엔 이어서 실제로 Prometheus 와 exporter 를 설치해 메트릭 데이터를 수집하고,
Grafana 를 통한 시각화를 진행해보도록 하겠습니다.
'Infrastructure > Prometheus' 카테고리의 다른 글
| 외부 Prometheus 가 Kubernetes 메트릭 수집하는 방법 (0) | 2025.04.20 |
|---|---|
| Prometheus Pushgateway with Node.Js (2) | 2021.04.10 |
| Node.js Cluster mode 모니터링 (0) | 2021.04.04 |
| Node.js 어플리케이션 모니터링 (0) | 2021.03.27 |
| Prometheus Node Exporter 모니터링 (0) | 2021.03.20 |



